본 글은 gasida님의 k8s-deploy 스터디 자료를 기반으로 작성되었습니다.
1. Cluster API란 무엇인가?
쿠버네티스를 운영해 본 사람이라면 다음과 같은 고민을 해본 적이 있을것 입니다.
- 새로운 클러스터를 만들 때마다 kubeadm init, join, CNI 설치, 인증서 관리 등 반복 작업 수행
- AWS 5개, GCP 3개, 온프레미스 2개 클러스터 운영 시 각각 다른 도구와 절차 필요
- 클러스터가 10개, 100개로 늘어난 경우 각각 버전 업그레이드, 노드 스케일링 관리 문제
이러한 문제를 해결하기 위해 등장한 것이 Cluster API(CAPI) 입니다.
쿠버네티스가 Pod를 관리하는 것처럼, 쿠버네티스 클러스터 자체도 쿠버네티스 리소스로 관리하자
우리가 Deployment YAML을 작성하면 쿠버네티스가 알아서 Pod를 생성하고 관리하듯이,
Cluster API에서는 Cluster라는 커스텀 리소스를 YAML로 정의하면 쿠버네티스 클러스터가 자동으로 프로비저닝됩니다.
- 명령형(Imperative): "서버 3대를 켜고, 거기에 kubeadm을 설치하고, init을 실행하고..."
→ 하나하나 명령을 내리는 방식 - 선언적(Declarative): "컨트롤 플레인 3대, 워커 노드 3대인 v1.34.3 클러스터를 만들고 싶어"
→ 원하는 상태(Desired State)만 정의하면 시스템이 알아서 맞춰주는 방식
선언적 관리는 쿠버네티스의 가장 큰 강점이며, Cluster API는 이 패러다임을 클러스터 인프라 관리 영역까지 확장한 기술입니다.
Cluster API 장점
- 선언적 클러스터 관리: YAML 하나로 클러스터의 전체 라이프사이클을 관리합니다.
- 인프라 추상화: 동일한 Cluster API 리소스 구조로 AWS, GCP, vSphere, 베어메탈 등 다양한 인프라에 클러스터를 프로비저닝할 수 있습니다.
- 자동 복구: MachineHealthCheck를 통해 노드 장애를 자동으로 감지하고 복구합니다.
- 표준화: ClusterClass를 통해 조직 내 클러스터 구성을 표준화할 수 있습니다. 보안 정책, 네트워크 설정, 컴포넌트 버전 등을 일관되게 관리합니다.
- Day-2 Operation: 버전 업그레이드, 스케일링, 인증서 교체 등 운영 작업을 쿠버네티스 네이티브 방식으로 처리합니다.
Cluster API가 적합한 경우
- 다수의 쿠버네티스 클러스터를 관리하는 플랫폼 팀
- 멀티 클라우드 또는 하이브리드 클라우드 환경에서 일관된 클러스터 관리가 필요한 경우
- GitOps 기반의 클러스터 라이프사이클 관리를 구현하고 싶은 경우
- 자동 복구, 자동 스케일링 등 자율적인 클러스터 운영을 원하는 경우
클러스터 수가 적거나 단일 환경에서 단순 운영을 하는 경우,
kubeadm이나 관리형 EKS/GKE/AKS 또는 Terraform 기반 프로비저닝이 더 단순하고 비용 효율적일 수 있습니다.
2. ClusterAPI 핵심 개념
Cluster API는 관리용 클러스터(Management Cluster)와 업무용 클러스터(Workload Cluster)로 구분되며,
Management Cluster는 Workload Cluster의 생성과 라이프사이클을 관리합니다.
(1) Management Cluster
관리 클러스터는 Cluster API의 컨트롤 타워 역할을 합니다.
- Cluster API의 컨트롤러(Controller)들이 실행되는 곳입니다.
- Cluster, Machine, MachineDeployment 등의 커스텀 리소스(CRD)가 이 클러스터에 설치됩니다.
- 이 클러스터 자체는 일반적인 쿠버네티스 클러스터이지만, Cluster API 컴포넌트가 설치되면서 관리 클러스터로 변환됩니다.
- 실제 비즈니스 애플리케이션은 여기서 실행하지 않는 것이 권장됩니다. 관리 전용으로 분리하는 것이 best pratice 입니다.
(2) Workload Cluster
워크로드 클러스터는 관리 클러스터에 의해 생성되고 관리되는 실제 클러스터입니다.
- 실제 비즈니스 애플리케이션이 배포되는 곳입니다.
- 관리 클러스터에 Cluster 리소스를 생성하면 자동으로 프로비저닝됩니다.
- 여러 개의 워크로드 클러스터를 하나의 관리 클러스터에서 관리할 수 있습니다.
┌─────────────────────────────────────┐
│ Management Cluster │
│ (Cluster API 컨트롤러들이 동작) │
│ │
│ capi-controller-manager │
│ capd-controller-manager (Docker) │
│ kubeadm-bootstrap-controller │
│ kubeadm-control-plane-controller │
└──────────────┬──────────────────────┘
│ 생성/관리
▼
┌──────────────────────────────────────────┐
│ Workload Cluster │
│ (실제 애플리케이션이 올라가는 클러스터) │
│ │
│ Control Plane × N │
│ Worker Node × N │
└──────────────────────────────────────────┘
3. Cluster API 아키텍처
Cluster API는 Provider 아키텍처를 기반으로 동작합니다.
이를 통해 AWS, GCP, Azure, Docker 등 다양한 인프라를 동일한 방식으로 다룰 수 있습니다.
4가지 Provider
(1) Core Provider (코어 프로바이더) — Cluster API
Cluster API의 두뇌 역할입니다.
- Cluster, Machine, MachineDeployment, MachineSet 등 핵심 CRD를 관리합니다.
- 전체 reconcile(조정) 오케스트레이션을 담당합니다.
- "컨트롤 플레인 3대, 워커 3대 클러스터를 만들어야 해"라는 의도를 받아 각 프로바이더에게 작업을 분배합니다.
(2) Infrastructure Provider (인프라 프로바이더) — 예: Docker, AWS, vSphere
실제 인프라 리소스를 생성하는 역할입니다.
- AWS라면 EC2 인스턴스를 생성하고, Docker(CAPD)라면 Docker 컨테이너를 생성합니다.
- 즉, 노드를 어디에, 어떤 형태로 만들 것인가를 담당합니다.
- 대표적인 인프라 프로바이더:
- CAPD (Cluster API Provider Docker) -> 개발/테스트 용도
- CAPA (Cluster API Provider AWS) -> AWS EC2 기반
- CAPV (Cluster API Provider vSphere) -> VMware vSphere 기반
- CAPZ (Cluster API Provider Azure) -> Azure VM 기반
(3) Bootstrap Provider (부트스트랩 프로바이더) — 예: Kubeadm
노드를 쿠버네티스 노드로 만들어주는 역할입니다.
- 인프라 프로바이더가 빈 서버(또는 컨테이너)를 만들면, 부트스트랩 프로바이더가 그 위에 쿠버네티스를 설치합니다.
- cloud-init user-data를 생성하거나, kubeadm init/join 설정 파일을 만들어 전달합니다.
- 기본적으로 kubeadm이 부트스트랩 프로바이더로 사용됩니다.
(4) Control Plane Provider (컨트롤 플레인 프로바이더) — 예: Kubeadm
컨트롤 플레인 노드를 전문적으로 관리하는 역할입니다.
- KubeadmControlPlane 리소스를 관리합니다.
- 컨트롤 플레인 노드의 스케일링(1대 → 3대), 버전 업그레이드, etcd 멤버 관리를 담당합니다.
- 컨트롤 플레인은 워커 노드와 달리 etcd, API Server 등 핵심 컴포넌트가 있어 별도의 전용 프로바이더가 관리합니다.
Provider 간 협업 흐름
사용자가 Cluster 리소스를 생성하면, 이 4가지 프로바이더가 다음과 같은 순서로 협력합니다.
사용자: "v1.34.3, CP 3대, Worker 3대 클러스터 만들어줘" (kubectl apply)
│
▼
[Core Provider] — 의도를 해석하고 작업 분배
│
├──→ [Control Plane Provider] — CP 노드 3대 생성 관리 시작
│ │
│ ├──→ [Infrastructure Provider] — Docker 컨테이너 3개 생성 (CP용)
│ │
│ └──→ [Bootstrap Provider] — kubeadm init/join 설정 생성 → 컨테이너에 전달
│
└──→ [MachineDeployment] — Worker 노드 3대 생성 관리
│
├──→ [Infrastructure Provider] — Docker 컨테이너 3개 생성 (Worker용)
│
└──→ [Bootstrap Provider] — kubeadm join 설정 생성 → 컨테이너에 전달
4. 핵심 리소스(CRD) 이해하기
Cluster API를 사용하면 관리 클러스터에 다양한 커스텀 리소스(CRD)가 설치됩니다.
각 리소스의 역할을 이해하면 Cluster API의 동작 원리가 명확해집니다.
Cluster
가장 상위 레벨의 리소스입니다. 하나의 워크로드 클러스터를 대표합니다.
- Pod CIDR, Service CIDR, Service Domain 등 클러스터 네트워크 설정을 포함합니다.
- 어떤 ClusterClass(설계도)를 사용할지, 컨트롤 플레인과 워커의 개수, 쿠버네티스 버전 등을 정의합니다.
apiVersion: cluster.x-k8s.io/v1beta2
kind: Cluster
metadata:
name: capi-quickstart
spec:
clusterNetwork:
pods:
cidrBlocks: ["10.10.0.0/16"]
services:
cidrBlocks: ["10.20.0.0/16"]
serviceDomain: myk8s-1.local
topology:
classRef:
name: quick-start # 사용할 ClusterClass
version: v1.34.3 # 쿠버네티스 버전
controlPlane:
replicas: 3 # 컨트롤 플레인 노드 수
workers:
machineDeployments:
- class: default-worker
name: md-0
replicas: 3 # 워커 노드 수ClusterClass
매번 클러스터를 만들 때마다 모든 설정을 처음부터 작성하는 것은 비효율적입니다.
ClusterClass는 클러스터의 표준 템플릿을 미리 정의해두고, 실제 클러스터를 만들 때는 이 템플릿을 참조하기만 하면 됩니다.
ClusterClass에는 다음이 정의됩니다.
- 어떤 인프라 템플릿을 사용할지 (DockerClusterTemplate, DockerMachineTemplate 등)
- 어떤 컨트롤 플레인 템플릿을 사용할지 (KubeadmControlPlaneTemplate)
- 어떤 부트스트랩 템플릿을 사용할지 (KubeadmConfigTemplate)
- 패치(Patches) - 변수에 따라 설정을 동적으로 변경하는 규칙
Patch는 ClusterClass의 핵심으로, 같은 설계도를 사용하면서 클러스터마다 다른 설정을 적용할 수 있게 해줍니다.
예를 들어,
- 클러스터 A는 imageRepository를 사내 레지스트리로 설정
- 클러스터 B는 기본 registry.k8s.io 사용
- 클러스터 C는 특정 etcdImageTag 버전 고정
이 차이를 하나의 ClusterClass에서 변수(Variables)와 패치(Patches)로 한번에 처리합니다.
ClusterClass (설계도)
├── 변수 정의: imageRepository, etcdImageTag, podSecurityStandard ...
├── 패치 규칙: imageRepository 지정 값 KubeadmControlPlane에 적용
└── 템플릿 참조: DockerClusterTemplate, KubeadmControlPlaneTemplate ...
Cluster A (실제 인스턴스) Cluster B (실제 인스턴스)
└── classRef: quick-start └── classRef: quick-start
└── variables: └── variables:
imageRepository: "my-registry.io" imageRepository: "" (기본값 사용)설계도 vs 실제 리소스
각 클러스터가 원본 템플릿을 공유하면 한 클러스터의 설정 변경이 다른 클러스터에 영향을 줄 수 있으므로, 원본 템플릿을 직접 수정하지 않고 복사본을 생성합니다.
예를 들어 DockerMachineTemplate을 조회하면 다음과 같은 결과가 나옵니다.
| 이름 | 역할 |
| quick-start-control-plane | ClusterClass에 정의된 원본 템플릿 (설계도) |
| quick-start-default-worker-machinetemplate | ClusterClass에 정의된 워커용 원본 템플릿 (설계도) |
| capi-quickstart-tdwjt | 실제 클러스터의 CP용 복사본 (실사용) |
| capi-quickstart-md-0-xgl7l | 실제 클러스터의 Worker용 복사본 (실사용) |
이것은 Cluster API의 Managed Topology 엔진이 다음과 같은 과정을 거치기 때문입니다.
- 사용자가 Cluster를 생성하면 ClusterClass(설계도)를 참조합니다.
- Cluster에 정의된 변수(Variables)와 패치(Patches)를 원본 템플릿에 적용합니다.
- 계산된 결과를 바탕으로 해당 클러스터 전용 템플릿을 자동 생성합니다.
Machine 관련 리소스 계층 구조
쿠버네티스에서 Deployment → ReplicaSet → Pod 계층이 있듯, Cluster API에도 비슷한 계층이 있습니다.
[워커 노드 관리 계층]
MachineDeployment ← Deployment에 해당, 롤링 업데이트 전략 정의
└── MachineSet ← ReplicaSet에 해당, 원하는 머신 수 유지
└── Machine ← Pod에 해당, 개별 노드(머신)를 표현
[컨트롤 플레인 관리 계층]
KubeadmControlPlane ← 컨트롤 플레인 전용, etcd 포함 관리
└── Machine ← 개별 CP 노드
MachineDeployment는 워커 노드 그룹을 관리합니다.
replicas: 3으로 설정하면 항상 3대의 워커 노드를 유지하고, 버전 업그레이드 시 롤링 업데이트를 수행합니다.
maxSurge와 maxUnavailable 같은 전략도 설정할 수 있어서, Deployment의 동작 방식과 매우 유사합니다.
MachineSet은 실제로 Machine 리소스의 수를 유지하는 역할을 합니다.
MachineDeployment에 의해 생성되며 ReplicaSet과 동일한 개념입니다.
Machine은 하나의 노드를 나타냅니다.
각 Machine은 bootstrap 설정(kubeadm 설정)과 infrastructureRef(실제 인프라 리소스 참조)를 가지고 있습니다.
MachineHealthCheck은 노드의 건강 상태를 지속적으로 모니터링합니다.
정의된 조건(예: NodeReady 상태가 5분 이상 False 또는 Unknown)에 해당하는 머신을 발견하면, 해당 머신을 자동으로 삭제하고 새 머신으로 교체합니다. ClusterClass에서 기본적으로 정의되어 있어, 별도로 설정하지 않아도 동작합니다.
5. 실습 환경 아키텍처: Docker Provider (CAPD)
이번 실습에서는 Docker 프로바이더(CAPD)를 사용합니다. CAPD는 개발 및 학습 목적으로 설계되었습니다.
실제 VM이나 클라우드 인스턴스 대신 Docker 컨테이너를 쿠버네티스 노드처럼 사용합니다.
[전체 구조]
# CP 노드 3대 + Worker 노드 3대인 경우
호스트 머신 (Docker 데몬)
│
├── [Docker 컨테이너] myk8s-control-plane ─── 관리 클러스터 (kind로 생성)
│ └── CAPI 컨트롤러들이 실행됨
│
├── [Docker 컨테이너] capi-quickstart-lb ───── HAProxy 로드밸런서
│ └── 워크로드 클러스터의 API Server 앞단 LB
│
├── [Docker 컨테이너] capi-quickstart-xxx-cp1 ─ 워크로드 클러스터 CP 노드 1
├── [Docker 컨테이너] capi-quickstart-xxx-cp2 ─ 워크로드 클러스터 CP 노드 2
├── [Docker 컨테이너] capi-quickstart-xxx-cp3 ─ 워크로드 클러스터 CP 노드 3
│
├── [Docker 컨테이너] capi-quickstart-md-0-xxx-w1 ─ 워크로드 클러스터 Worker 1
├── [Docker 컨테이너] capi-quickstart-md-0-xxx-w2 ─ 워크로드 클러스터 Worker 2
└── [Docker 컨테이너] capi-quickstart-md-0-xxx-w3 ─ 워크로드 클러스터 Worker 3
관리 클러스터는 kind(Kubernetes in Docker)로 미리 생성해두고, 해당 클러스터에 Cluster API를 설치합니다.
이후 워크로드 클러스터의 각 노드는 Docker 컨테이너로 생성됩니다.
컨트롤 플레인 앞단의 HAProxy 로드밸런서
Cluster API Docker Provider는 HAProxy 로드밸런서 컨테이너를 자동으로 생성하여 워크로드 클러스터의 컨트롤 플레인 API Server 앞에 배치합니다.
kubectl 명령 → HAProxy (192.168.97.3:6443) → CP노드1 (192.168.97.4:6443)
→ CP노드2 (192.168.97.5:6443)
→ CP노드3 (192.168.97.6:6443)
HAProxy는 /healthz 엔드포인트로 헬스체크를 수행하며, 정상인 API Server에만 트래픽을 분배합니다.
HAProxy Stats 페이지를 통해 각 백엔드의 상태를 실시간으로 모니터링할 수도 있습니다.
6. 실습 진행
실습 목표
WSL2 + Docker 환경에서 kind로 관리 클러스터를 구성하고, Cluster API로 워크로드 클러스터를 배포합니다.
본 실습에서는 WSL2 환경의 메모리 제약으로 CP 1대 + Worker 1대로 구성합니다.
(HA 구성 테스트 시 CP 3대 + Worker 3대 권장)
실습 환경
- OS: Windows 11 + WSL2 (Ubuntu)
- Docker : Docker Desktop (unix:///var/run/docker.sock)
- Tools : kind v0.27, kubectl, clusterctl v1.12.2
- CAPI Version : Cluster API v1.12.2
Cluster API 구성
- Management Cluster : kind (v1.35.0)
- Workload Cluster : CP 1대 + Worker 1대 (v1.34.3)
- Infrastructure Provider : CAPD (Docker)
- Bootstrap / CP Provider : Kubeadm
- CNI : Calico v3.27
[Step 1] Management 클러스터 생성 (kind)
먼저 kind를 사용하여 관리 클러스터로 사용할 쿠버네티스 클러스터를 생성합니다.
여기서 핵심은 Docker 소켓 /var/run/docker.sock을 컨테이너 안으로 마운트하는 것입니다.
관리 클러스터(kind container) 안에서 실행되는 CAPD Controller가 호스트의 Docker 데몬에 접근하여 새로운 컨테이너(워크로드 클러스터 노드)를 생성해야 하기 때문입니다.
$ docker context ls
NAME DESCRIPTION DOCKER ENDPOINT ERROR
default * Current DOCKER_HOST based configuration unix:///var/run/docker.sock
desktop-linux Docker Desktop npipe:////./pipe/dockerDesktopLinuxEngine
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
$ kind create cluster --name myk8s --image kindest/node:v1.35.0 --config - <<EOF
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraMounts:
- hostPath: /var/run/docker.sock
containerPath: /var/run/docker.sock
extraPortMappings:
- containerPort: 30000
hostPort: 30000
- containerPort: 30001
hostPort: 30001
EOF
[Step 2] clusterctl 및 Cluster API 설치
먼저 clusterctl을 설치해줍니다. clusterctl은 Cluster API의 CLI 도구입니다.
curl -L https://github.com/kubernetes-sigs/cluster-api/releases/download/v1.12.2/clusterctl-linux-amd64 -o clusterctl
sudo install -o root -g root -m 0755 clusterctl /usr/local/bin/clusterctl
init 명령으로 현재 쿠버네티스 클러스터에 Cluster API 컴포넌트를 설치합니다.
export CLUSTER_TOPOLOGY=true # Enable the experimental Cluster topology feature
clusterctl init --infrastructure docker # Initialize the management cluster
이 명령이 실행되면 관리 클러스터에 다음 pod들이 배포됩니다.
- cert-manager: 각 컨트롤러의 Webhook 서버에 필요한 TLS 인증서를 자동 발급하고 관리합니다.
- capi-system: Core Provider. 핵심 CRD와 메인 컨트롤러가 설치됩니다.
- capd-system: Infrastructure Provider (Docker). Docker 컨테이너를 생성하는 컨트롤러입니다.
- capi-kubeadm-bootstrap-system: Bootstrap Provider. kubeadm 설정을 생성하는 컨트롤러입니다.
- capi-kubeadm-control-plane-system: Control Plane Provider. 컨트롤 플레인 노드를 관리하는 컨트롤러입니다.
4개의 Provider와 pod가 설치된 것을 확인할 수 있습니다.



cert-manager가 필요한 이유
Cluster API의 각 프로바이더는 Kubernetes Admission Webhook을 사용합니다.
Webhook은 리소스가 생성되거나 수정될 때 검증이나 기본값 설정을 수행하는데, 이 Webhook 서버는 반드시 HTTPS로 통신해야 합니다. cert-manager는 이 Webhook 서버들에 필요한 TLS 인증서를 자동으로 발급하고 갱신합니다.
각 프로바이더 네임스페이스마다 Self-Signed Issuer와 Certificate가 하나씩 생성됩니다.
capd-system → capd-selfsigned-issuer
capi-system → capi-selfsigned-issuer
capi-kubeadm-bootstrap-system → capi-kubeadm-bootstrap-selfsigned-issuer
capi-kubeadm-control-plane-system → capi-kubeadm-control-plane-selfsigned-issuer
[Step 3] 워크로드 클러스터 생성
clusterctl generate 명령으로 워크로드 클러스터 YAML을 생성합니다.
# 첫 번째 워크로드 구성을 위한 환경 변수 설정
export SERVICE_CIDR=["10.20.0.0/16"]
export POD_CIDR=["10.10.0.0/16"]
export SERVICE_DOMAIN="myk8s-1.local"
export POD_SECURITY_STANDARD_ENABLED="false"
# Generating the cluster configuration : yaml 파일 생성 (--dry-run)
clusterctl generate cluster capi-quickstart --flavor development \
--kubernetes-version v1.34.3 \
--control-plane-machine-count=1 \
--worker-machine-count=1 \
> capi-quickstart.yaml
# 생성된 YAML의 종류 확인
cat capi-quickstart.yaml | grep -E '^apiVersion:|^kind:'
# 클러스터 배포 (워크로드 클러스터 프로비저닝)
kubectl apply -f capi-quickstart.yaml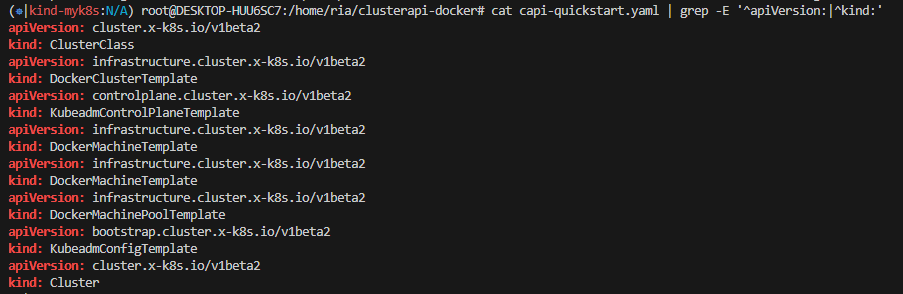
생성된 YAML에는 다음 리소스들이 포함됩니다.
| 리소스 | 역할 |
| ClusterClass | 클러스터의 표준 설계도 |
| DockerClusterTemplate | Docker 기반 클러스터 인프라 템플릿 |
| KubeadmControlPlaneTemplate | 컨트롤 플레인 부트스트랩 템플릿 |
| DockerMachineTemplate (CP용) | CP 노드의 Docker 컨테이너 설정 |
| DockerMachineTemplate (Worker용) | Worker 노드의 Docker 컨테이너 설정 |
| KubeadmConfigTemplate | kubeadm join 설정 템플릿 |
| Cluster | 실제 워크로드 클러스터 인스턴스 정의 |
Control Plane 노드가 1대여도 HAProxy LB 컨테이너(capi-quickstart-lb)는 생성됩니다.
CP를 3대로 늘리면 LB의 haproxy.cfg에 서버가 자동으로 추가/제거됩니다.

[Step 4] CNI 플러그인 설치
Cluster API는 쿠버네티스 클러스터를 프로비저닝하지만, CNI(Container Network Interface) 플러그인은 설치하지 않습니다.
워크로드 클러스터의 kubeconfig를 가져와서 CNI를 설치합니다.
# 워크로드 클러스터 자격증명
clusterctl get kubeconfig capi-quickstart > capi-quickstart.kubeconfig
# 노드들 상태 not ready -> cni 플러그인 설치
kubectl --kubeconfig=capi-quickstart.kubeconfig apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.0/manifests/calico.yaml
kubectl --kubeconfig=capi-quickstart.kubeconfig get nodes -owide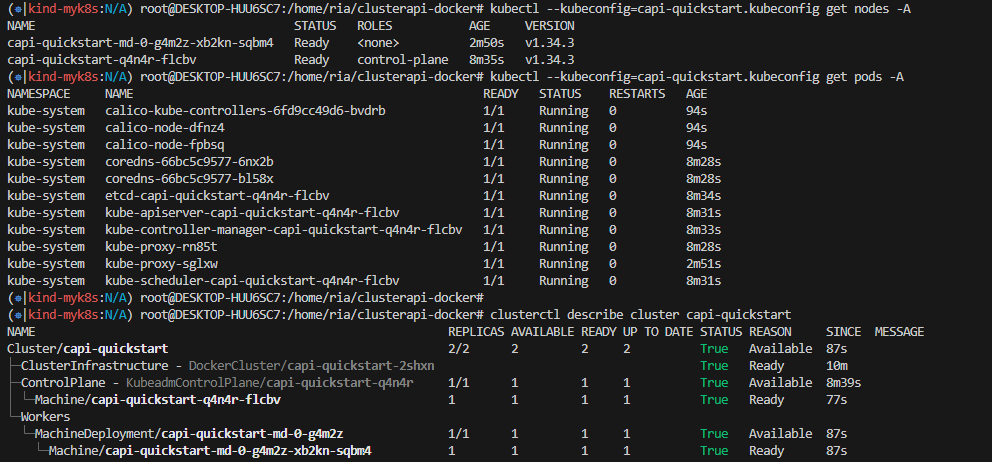
CNI 설치 후 모든 노드가 Ready 상태가 되면, 워크로드 클러스터 프로비저닝이 완료된 것입니다.
[Step 5] 클러스터 업그레이드
ClusterClass / Topology 구조를 쓰고 있으므로 KubeadmControlPlane이나 MachineDeployment를 직접 수정하지 않고 Cluster 리소스의 version 필드를 변경합니다. 다음 명령을 수행하면 롤링 업그레이드가 수행됩니다.
kubectl patch cluster capi-quickstart --type merge -p '{"spec":{"topology":{"version":"v1.35.0"}}}'
업그레이드는 컨트롤 플레인부터 진행됩니다.
1. 새 버전(v1.35.0) CP 노드 컨테이너 생성
2. 새 노드 Ready 확인
3. 구 버전(v1.34.3) CP 노드 삭제
4. Worker 노드도 동일하게 순차 교체
(업그레이드 전)
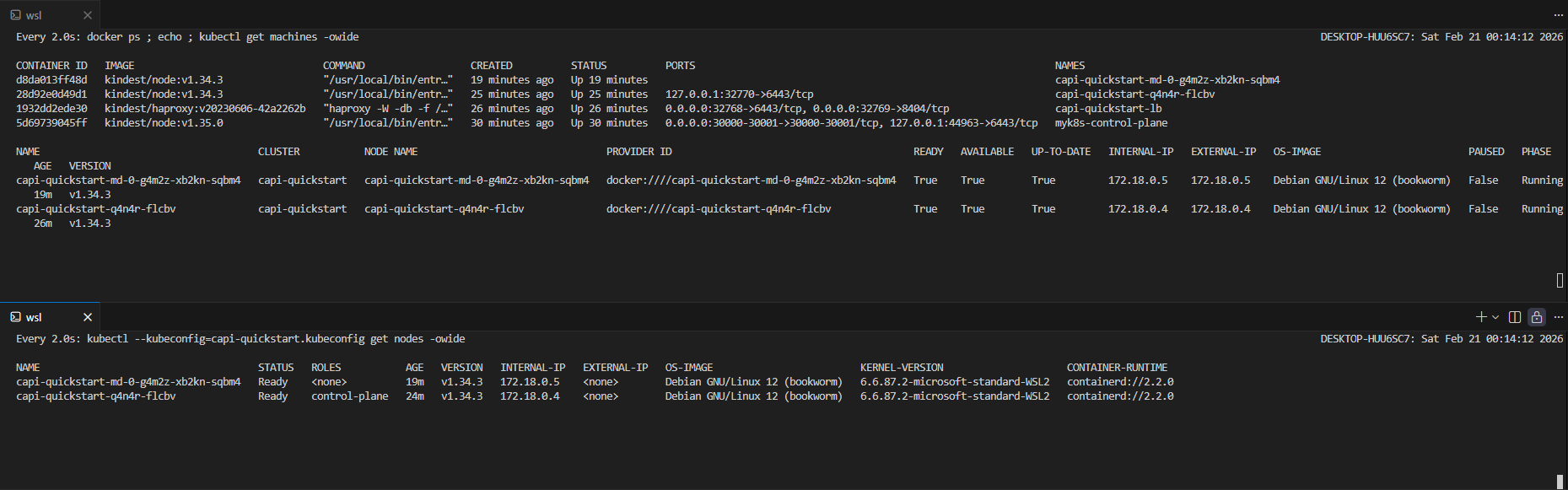
(업그레이드 후)
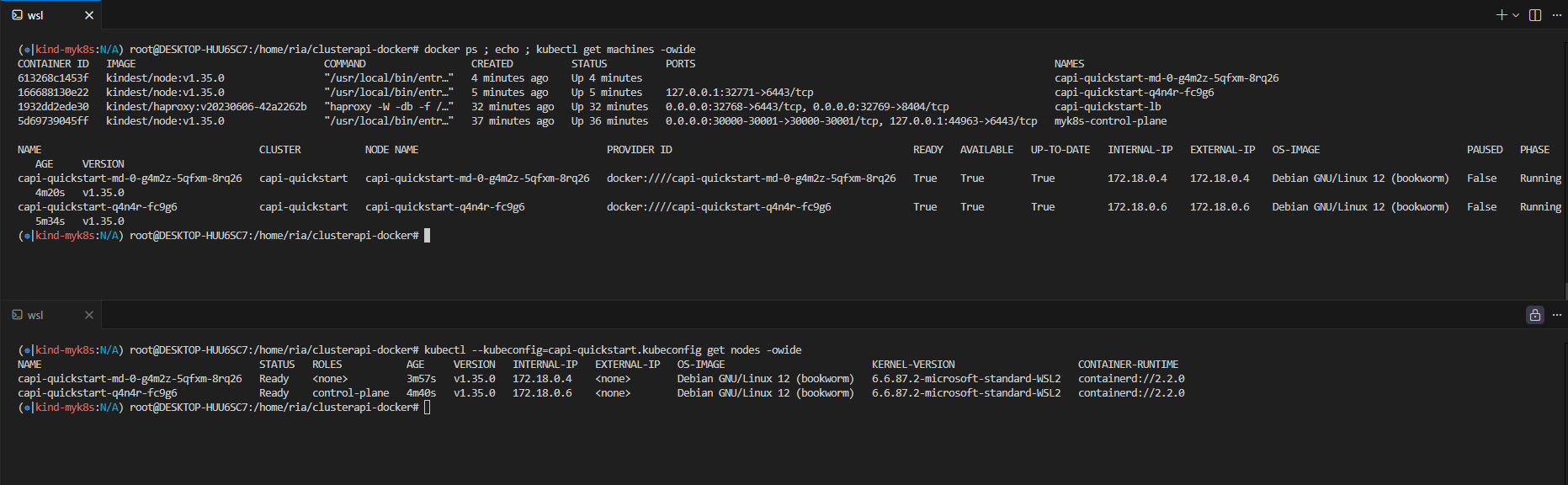
업그레이드 전/후 HAProxy 설정을 비교하면 백엔드 서버가 자동으로 교체된 것을 확인할 수 있습니다.
$ diff haproxy_before.cfg haproxy.cfg
40c40
< server capi-quickstart-q4n4r-flcbv 172.18.0.4:6443 weight 100 check check-ssl verify none resolvers docker resolve-prefer ipv4
---
> server capi-quickstart-q4n4r-fc9g6 172.18.0.6:6443 weight 100 check check-ssl verify none resolvers docker resolve-prefer ipv4
7. 워크로드 클러스터 내부 구조 분석
컨트롤 플레인 노드 내부
생성된 워크로드 클러스터의 컨트롤 플레인 노드(Docker 컨테이너) 내부를 살펴보면 일반적인 kubeadm으로 설치한 쿠버네티스 클러스터와 동일한 구조입니다.
ConfigMap (kubeadm-config)
clusterName: capi-quickstart
controlPlaneEndpoint: <HAProxy IP>:6443
networking:
dnsDomain: myk8s-1.local
podSubnet: 10.10.0.0/16
serviceSubnet: 10.20.0.0/16
featureGates:
ControlPlaneKubeletLocalMode: true
ControlPlaneKubeletLocalMode
kubelet이 API Server에 의존하지 않고 로컬 Manifest 파일을 기반으로 컨트롤 플레인 Pod를 기동하도록 하는 방식입니다.
API Server가 아직 살아있지 않은 초기 부팅 단계에서도 kubelet이 로컬 설정만으로 컨트롤 플레인을 구성할 수 있습니다.
etcd 구성
CP 1대 구성에서는 etcd도 단일 노드로 실행됩니다. CP를 3대로 스케일 아웃하면 etcd도 자동으로 3노드 클러스터로 확장됩니다.
# CP 1대일 때
etcd member list:
capi-quickstart-xxx-cp1 | https://<CP 노드 IP>:2380
워커 노드 내부
워커 노드는 kubelet과 containerd만 실행됩니다.
- kubelet은 HAProxy 로드밸런서를 통해 API Server에 접근합니다. CP 노드에 직접 연결하지 않습니다.
- containerd v2.2.0이 사용되며, overlayfs 스냅샷터와 systemd cgroup을 사용합니다.
- eviction-hard 설정이 0%로 되어 있는 것은 Docker 환경에서 디스크 부족으로 인한 불필요한 eviction을 방지하기 위함입니다.
인증서 관리
Cluster API는 관리 클러스터에 워크로드 클러스터의 모든 인증서를 Secret으로 저장합니다.
| Secret | Description |
| capi-quickstart-ca | 클러스터 CA 인증서 및 키 |
| capi-quickstart-etcd | etcd CA 인증서 및 키 |
| capi-quickstart-sa | ServiceAccount 서명 키 |
| capi-quickstart-proxy | front-proxy CA 인증서 및 키 |
| capi-quickstart-kubeconfig | 클러스터 접근용 kubeconfig |
| capi-quickstart-xxx-cp1 | CP 노드의 cloud-init 데이터 (인증서+kubeadm 설정 포함) |
| capi-quickstart-md-0-xxx-w1 | Worker 노드의 cloud-init 데이터 |
각 노드의 Secret에는 cloud-init 형식의 데이터가 담겨 있습니다. 이 데이터에는 필요한 인증서 파일의 내용과 kubeadm join 설정이 포함되어 있어, 노드가 부팅되면 자동으로 클러스터에 참여할 수 있습니다.
8. Cluster API v1.12의 새로운 기능
이번 CAPI v1.12 버전에서 두 가지 기능이 추가되었습니다.
In-place Updates
기존 CAPI는 변경 사항이 생기면 무조건 노드를 새로 만들고 기존 노드를 삭제하는 불변 롤아웃 방식이었습니다. v1.12부터는 Runtime Extension을 통해 노드를 교체하지 않고 현재 노드에서 직접 변경하는 것도 가능해졌습니다. 사용자 크리덴셜 변경처럼 노드 재생성이 불필요한 경우에 유용합니다.
Chained Upgrades
기존에는 v1.32 → v1.33 → v1.34 → v1.35 처럼 한 단계씩 업그레이드해야 했습니다. v1.12부터는 목표 버전만 지정하면 CAPI가 중간 단계를 알아서 계획하고 순서대로 실행합니다. 1년에 한 번씩 업그레이드하는 환경에서 특히 유용합니다.
'Kubernetes' 카테고리의 다른 글
| [Kubernetes] 폐쇄망(Air-Gap) 환경에서 k8s 실습 환경 구성 (0) | 2026.02.14 |
|---|---|
| [Kubespray] Kubernetes HA 구성 실습 (0) | 2026.02.07 |
| [Kubespray] Kubernetes 자동 설치 실습 (v1.33) (0) | 2026.01.31 |
| [kubeadm] Kubernetes 버전 업그레이드 (1.32 -> 1.35) (0) | 2026.01.22 |
| Kubernetes 설치 과정에서 등장하는 용어 정리 (0) | 2026.01.19 |