1. Kubernetes 설치 전 swap을 끄세요 (swapoff)
Swap = 가상 메모리
- RAM(물리 메모리)이 부족할 때 디스크의 일부를 메모리처럼 사용하는 기능
- RAM이 8GB인데 10GB가 필요한 경우, 2GB를 디스크(Swap)에 임시 저장
# Swap 상태 확인
free -h
total used free shared buff/cache available
Mem: 7.7Gi 2.1Gi 3.2Gi 123Mi 2.4Gi 5.1Gi
Swap: 2.0Gi 0B 2.0Gi # ← Swap 영역
일반 서버/PC 환경에서 swap이 유용한 이유
- RAM 부족 시 디스크를 사용하다보면 속도는 느려질 수는 있지만, 메모리 부족으로 시스템 전체가 다운되는건 막을 수 있을 수 있습니다.
Kubernetes 설치 시 왜 swap을 꺼야 할까요?
- Kubernetes는 노드 자원을 직접 통제하고 관리할 수 있어야 합니다.
- Swap은 이 통제권을 OS에게 넘겨버리는 행위이므로 클러스터의 안정성을 위해 꼭 비활성화 해야 합니다.
1. 리소스/성능 예측 불가능
resources:
requests:
memory: 1Gi # 최소 필요 메모리
limits:
memory: 2Gi # 최대 사용 가능 메모리- Swap을 키면 Pod가 메모리를 초과 사용해도 죽지 않고 디스크를 쓰면서 버팀
- Kubernetes는 정상 Pod로 인식, 리소스 사용량 예측 불가능
2. Kubernetes의 리소스 관리 철학
- 정상적인 리소스 관리 방법 - 메모리가 부족하면, Pod를 즉시 종료(OOMKilled) 시키고 다른 노드에서 재시작
- 하지만 Swap이 켜져 있으면, 죽지 않고(재스케줄링 되지 않고) 느린 상태로 계속 실행 됨
- 스케줄링 판단 오류 -> 노드 병목 지점 -> 전체 클러스터 성능 저하
2. OverlayFS 모듈을 활성화 하세요
OverlayFS = 여러 파일시스템 레이어를 하나로 겹쳐 보이게 만드는 기술
[최종 보이는 파일시스템]
↑
┌────┴────┐
[Upper Layer] ← 컨테이너 내부 변경사항 (읽기/쓰기)
[Lower Layer] ← 이미지 원본 (읽기 전용)- Lower Layer
- 컨테이너 이미지
- 읽기 전용
- Upper Layer
- 컨테이너 실행 중 발생한 변경 사항
- 읽기/쓰기 가능
=> 컨테이너 안에서는 이 두 Layer가 하나의 파일시스템처럼 보입니다.
동작 방식
- Base Image(Lower Layer)는 수정되지 않음
- 컨테이너에서 파일을 새로 만들면, Upper Layer 생성됨
- 기본 이미지 내 파일을 수정하면, Lower를 Upper로 복사 후 Upper 복사본을 수정
- 컨테이너가 삭제되면, Uppder Layer만 사라지고 Lower Layer는 그대로 유지
=> 이미지 재사용이 쉬워지고, 컨테이너는 가벼워집니다.
Kubernetes에서 OverlayFS가 필요한 이유
1. 컨테이너 이미지 생성
- 컨테이너 이미지는 레이어 단위로 만들어짐 (각 명령어가 하나의 레이어)
- OverlayFS는 이 레이어들을 하나로 합쳐서 보여주는 역할을 합니다.
FROM ubuntu:20.04 # Lower Layer 1 (100MB)
RUN apt-get update # Lower Layer 2 (50MB)
RUN apt-get install nginx # Lower Layer 3 (30MB)
COPY app.py /app/ # Lower Layer 4 (1MB)
2. 디스크 공간 절약
- 같은 이미지를 쓰는 컨테이너가 많아질수록 디스크 효율 차이가 커집니다.
# 같은 Base Image 사용하는 컨테이너 100개
ubuntu:20.04 (100MB) ← 이건 한번만 저장
↓
Container 1 (변경사항만 1MB)
Container 2 (변경사항만 2MB)
Container 3 (변경사항만 1MB)
...- OverlayFS 없는 경우,
- 100MB × 컨테이너 수
- OverlayFS 있는 경우,
- 100MB + 각 컨테이너의 변경분만 추가
3. 컨테이너 시작 속도
- OverlayFS를 사용하면 전체 파일 시스템을 복사하지 않아도 됩니다.
- 컨테이너가 시작하면 레이어 마운트를 수행하여 수백개 컨테이너도 빠르게 기동시킬 수 있습니다.
OverlayFS 모듈 활성화란?
- OverlayFS는 Linux 커널 기능입니다.
- 커널에 overlay 모듈이 있어야 containerd가 OverlayFS를 사용할 수 있습니다.
일반 서버에서 OverlayFS가 활성화 되어 있지 않은 이유
- 컨테이너를 안 쓰는 서버가 많고, 기본적으로 불필요한 커널 기능은 로드하지 않음
- 메모리 절약과 안정성을 위해 OverlayFS 비활성화
컨테이너 런타임(containerd)은 OverlayFS 반드시 필요
- Docker나 containerd는 OverlayFS 없이 정상 동작 불가
- /merged 디렉터리 - 컨테이너에서 보는 최종 파일시스템 (Lower+Upper를 overlayfs로 합쳐서 만든 최종 뷰)
- lower에 있던 파일들, upper에 새로 생긴 파일들, upper가 덮어쓴 파일들 모두 /merged를 통해서 볼 수 있음
- 컨테이너는 그냥 하나의 파일시스템이라고 인식
# Docker에서 overlay 사용 확인
docker info | grep -i storage
Storage Driver: overlay2
# Overlay 마운트 확인
mount | grep overlay
overlay on /var/lib/docker/overlay2/xxxxx/merged type overlay ...
OverlayFS 모듈 확인하고 활성화하기
# 커널 모듈 로드 여부 확인
lsmod | grep overlay
# 없으면 로드
sudo modprobe overlay
# 부팅 시 자동 로드 설정
cat <<EOF | sudo tee /etc/modules-load.d/containerd.conf
overlay
br_netfilter
EOF
3. containerd의 Snapshotter를 확인하고 설정하세요
Snapshotter = 컨테이너 이미지의 레이어를 스냅샷 단위로 관리하는 시스템
- containerd 내부 컴포넌트
- 컨테이너가 실행되면 snapshotter는 이미지의 레이어와 컨테이너용 쓰기 레이어 경로를 정의하여 OverlayFS에 마운트 명령
- OverlayFS 커널 모듈이 명령을 받아 실제 레이어 합치는 작업 실행
Snapshotter는 언제 필요할까?
1. 이미지 Pull 할 때
- Layer = 스냅샷 체인
- Layer가 3개인 nginx 이미지를 pull 하는 경우, Snopshotter은 다음과 같은 일을 수행합니다.
# nginx 이미지 pull
docker pull nginx
# Snapshotter가 하는 일
1. Layer 1 다운로드 → 스냅샷 생성
2. Layer 2 다운로드 → 이전 스냅샷 위에 추가
3. Layer 3 다운로드 → 이전 스냅샷 위에 추가
2. 컨테이너 실행할 때
- OverlayFS - Layer를 합쳐서 보여주는 커널 기능
- Snapshotter - 어떤 Layer를 어떻게 쌓을지 결정하는 관리자
docker run nginx
# Snapshotter가 하는 일:
1. nginx 이미지의 모든 읽기 전용 스냅샷 가져오기
2. 스냅샷 순서대로 쌓기
3. 맨 위에 쓰기 가능한 컨테이너 레이어(스냅샷) 추가
4. 이 구조를 컨테이너 rootfs로 마운트
Containerd의 Snapshotter 종류
- containerd는 여러 Snapshotter 구현체를 제공합니다.
- 대부분 기본값으로 'overlayfs'가 선택되지만, 운영 환경에서는 어떤 기술이 사용되는지 직접 확인하고 명시하는 것이 좋습니다.
- (주의) 커널에 overlayfs 모듈이 없거나 특정 제약에 걸려 native로 fallback 하는 경우, 컨테이너 생성이 느려지거나 디스크 사용량이 급증할 수 있습니다.
# containerd 설정 확인
cat /etc/containerd/config.toml | grep snapshotter| Snapshotter | 특징 | 사용 환경 |
| overlayfs | 빠르고 효율적 (사실상 표준) | 리눅스 대부분 |
| native | 파일 복사 방식 (느림) | overlayfs 불가 환경 |
| btrfs | Btrfs 스냅샷 기능 활용 | Btrfs 사용 시 |
| zfs | ZFS 스냅샷 기능 활용 | ZFS 사용 시 |
| devmapper | Device Mapper 기반 | 구형 RHEL |
'overlayfs' Snapshotter 스냅샷 구조
- 각 레이어는 부모 스냅샷을 가리키는 체인 구조로, 이미지 레이어 순서를 그대로 볼 수 있습니다.
# containerd 스냅샷 목록 보기
sudo ctr -n k8s.io snapshots ls
# 예시 출력:
KEY PARENT
sha256:abc123... -
sha256:def456... sha256:abc123...
sha256:ghi789... sha256:def456...
실제 파일 위치
ls -la /var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/
1/
├─ fs/ # 실제 파일 데이터
└─ work/ # Overlay 작업용
2/
├─ fs/
└─ work/
...
# 이 디렉터리들이 OverlayFS의 Lower / Upper 레이어 재료가 됩니다.
Kubernetes에서의 Snapshotter의 역할
- Pod 실행 시, Snapshotter가 하는 일은 다음과 같습니다.
apiVersion: v1
kind: Pod
spec:
containers:
- name: nginx
image: nginx:latest
---
# Pod 생성 시 Snapshotter가 하는 일
1) Image Pull
kubelet → containerd → snapshotter
"nginx 이미지 받아서 스냅샷으로 저장해"
(각 레이어를 스냅샷으로 관리)
2) Container 생성
kubelet → containerd → snapshotter
"이 스냅샷들로 rootfs 만들어줘"
(읽기 전용 스냅샷 쌓고 쓰기 가능한 컨테이너 스냅샷 추가)
# Pod 삭제 시 Snapshotter가 하는 일
kubelet → containerd → snapshotter
"컨테이너 지워줘"
(컨테이너 쓰기 레이어만 삭제하고, 이미지 스냅샷은 그대로 유지)
Snapshotter 설정 방법
- overlayfs 기반 snapshotter를 사용하려면 다음과 같이 설정합니다.
# containerd config 파일 생성
sudo containerd config default | sudo tee /etc/containerd/config.toml
# 버전 확인
containerd --version
# 적용
## containerd 2.x
version = 3
[plugins.'io.containerd.cri.v1.images']
snapshotter = "overlayfs"
## containerd 1.x
version = 2
[plugins."io.containerd.grpc.v1.cri".containerd]
snapshotter = "overlayfs"
# containerd 재시작
sudo systemctl restart containerd
4. kubelet과 containerd의 cgroup 드라이버를 확인하고 통일하세요
Cgroup = Control Group의 약자로, 프로세스의 리소스를 제한·격리·모니터링하는 Linux 커널 기능
- 프로세스의 CPU, Limit 리소스 제한을 어플리케이션이 아닌 커널 레벨에서 통제
- 주로 Container의 Resource 제어를 위해서 많이 사용
- Container가 생성되면 생성된 Container의 Process들을 담당하는 Container Cgroup이 생성
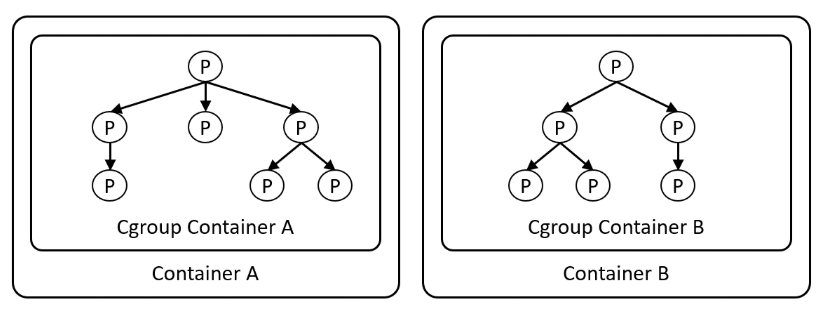
(Container 내부 Process들이 Fork System Call을 통해 Child Process들을 생성해도, 생성된 Child Process들 모두 Container Cgroup에 소속되어 있기 때문에 Container의 Resource를 제어하려면 Container Cgroup을 제어하면 됨)
Cgroup은 누가 관리할까? 두 가지 Cgroup Driver가 있다
1. cgruopfs Driver
- Cgroup 자체는 커널 기능.
- 커널 기능은 사용자가 직접 접근할 수 없기 때문에 리눅스는 'cgroupfs'라는 가상 파일시스템 제공
- 사용자는 이 파일시스템에 값을 읽고 쓰는 방식으로 cgroup 동작을 설정하고 확인할 수 있습니다.
- cgruopfs 활성화 시 container runtime 또는 kubelet이 직접 cgroupfs를 통해서 Cgroup 제어
- /sys/fs/cgroup/ 경로를 직접 생성하고 조작, 단순하고 직관적.
/sys/fs/cgroup/memory/docker/<container-id>/
└─ memory.limit_in_bytes
2. systemd Driver
- systemd를 통해서 Cgroup 제어
- container runtime은 systemd에게 해당 경로에 컨테이너를 넣어달라 요청
- 컨테이너 생성 시 systemd가 만든 cgroup 디렉터리 아래에 포함
- systemd는 현재 Kubernetes에서 권장되는 방식으로 OS 프로세스, 서비스, 컨테이너를 하나의 체계로 관리합니다.
kubepods.slice
└─ kubepods-pod<uid>.slice
└─ container.scope
여기서 문제가 될수 있는 상황은?
1) kubelet과 containerd, 두 컴포넌트가 서로 다른 cgroup 관리 방식을 사용하는 경우 (과거 문제)
- kubelet과 containerd가 서로 다른 cgroup 트리를 관리
- 서로 다른 경로를 모니터링 하고 있어 실제 사용량 파악이 불가
- cgroupfs이나 systemd로 통일
2) systemd가 init 시스템인 환경 (현재 문제)
- 과거에는 kubelet과 containerd 두 컴포넌트만 동일한 cgroup 드라이버를 사용하면 됐었음
- 현재 대부분의 리눅스 배포판은 systemd를 init 시스템(PID 1)으로 사용하며 systemd가 시스템 전체의 cgroup 관리자가 됨
- 이 환경에서 kubelet과 containerd가 cgroupfs 방식으로 직접 /sys/fs/cgroup을 조작하면, systemd가 인지하지 못하는 cgroup이 생성되거나 관리 권한 충돌
그래서 systemd가 init 시스템인 환경에서는 kubelet과 containerd 모두 'systemd' 드라이버로 통일하는 것을 권장합니다.
Kubernetes에서 Cgroup 드라이버 설정하기 (k8s 권장 조합 : systemd + systemd)
1) 먼저, 커널이 쓰는 Cgroup 버전 확인
- cgroup v2는 v1과 달리 모든 리소스를 하나의 트리로 통합
- cpu/memory/IO 모두 같은 cgroup 노드에서 관리하고, 관리자는 한명만 두어 일관되게 관리할 수 있어야함
- 즉, cgroup v2는 'systemd'식 관리 모델을 전제로 설계되었음
=> systemd를 권장하는 이유는 systmed가 init 시스템인 이유도 있지만 이처럼 cgroup v2인 경우에도 systmed를 쓰는 것이 좋습니다.
stat -fc %T /sys/fs/cgroup
cgroup2fs
findmnt
mount | grep cgroup
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,...)
2) systemd가 cgroup을 실제로 관리중인지 확인
systemd-cgls --no-pager
3) containerd, kubelet의 cgroup 드라이버를 systemd로 설정
containerd
#기본 설정 파일 생성
containerd config default | tee /etc/containerd/config.toml
#확인
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
#false인 경우 true로 수정 후 containerd restart
cat /etc/containerd/config.toml | grep -i systemdcgroup
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
systemctl restart containerd
kubelet
# kubeadm에서는 기본값 systemd
--cgroup-driver=systemd
ps aux | grep kubelet | grep cgroup-driver
kubectl describe node | grep -i cgroup
출처
gasida님 k8s-deploy 스터디 자료
Cgroup Driver 선택하기 - tech.kakao.com
'Kubernetes' 카테고리의 다른 글
| [Kubespray] Kubernetes HA 구성 실습 (0) | 2026.02.07 |
|---|---|
| [Kubespray] Kubernetes 자동 설치 실습 (v1.33) (0) | 2026.01.31 |
| [kubeadm] Kubernetes 버전 업그레이드 (1.32 -> 1.35) (0) | 2026.01.22 |
| [Ansible] 개념 정리 및 실습 (0) | 2026.01.17 |
| [Kubernetes The Hard Way] k8s 수동 설치로 컴포넌트 구조와 동작 이해하기 (0) | 2026.01.10 |
